Today I am delighted to announce the first release of H2O, version 0.9.0; this is a christmas gift from me.
H2O is an optimized HTTP server with support for HTTP/1.x and the upcoming HTTP/2; it can be used either as a standalone server or a library.
Built around PicoHTTPParser (a very efficient HTTP/1 parser), H2O outperforms Nginx by a considerable margin. It also excels in HTTP/2 performance.

Why do we need a new HTTP server? The answer is because its performance does matter in the coming years.
It is expected that the number of files being served by the HTTP server will dramatically increase as we transit from HTTP/1 to HTTP/2.
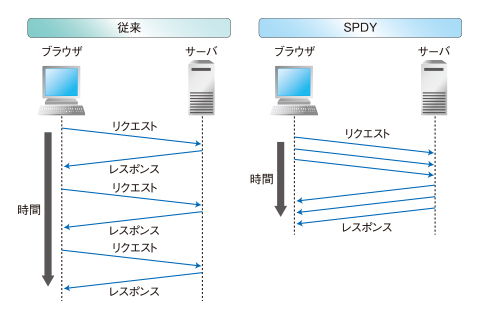
This is because current techniques used to decrease the number of asset files (e.g. CSS sprites and CSS concatenation) becomes a drag in page rendering speed in HTTP/2. Such techniques were beneficial in HTTP/1 since the protocol had difficulty in utilizing all the available bandwidth. But in HTTP/2 the issue is fixed, and the overhead of transmitting all the images / CSS styles used by the website at once while only some of them is needed to render a specific page, becomes a bad idea. Instead, switching back to sending small asset files for every required element consisting the webpage being request becomes an ideal approach.
Having an efficient HTTP/1 server is also a good thing, as we large-scale adopt the idea of Microservices; it increases the number of HTTP requests transmitted within the datacenter.
As shown in the benchmark charts, H2O is designed with these facts in mind, making it (as we believe) an ideal choice of HTTP server of the future.
With this first release, H2O is concentrates on serving static files / working as a reverse proxy at high performance.
Together with the contributors I will continue to optimize / add more features to the server, and hopefully reach a stable release (version 1.0.0) when HTTP/2 becomes standardized in the coming months.
Stay tuned.
PS. It is also great that the tools developed by H2O is causing other effects; not only have we raised the bar on HTTP/2 server performance (nghttp2 (a de-facto reference implementation of HTTP/2) has become much faster in recent months), the performance race of HTTP/1 parser has once again become (Performance improvement and benchmark by indutny · Pull Request #200 · joyent/http-parser, Improving PicoHTTPParser further with AVX2), @imasahiro is working on merging qrintf (a preprocessor that speeds up the sprinf(3) family by a magnitude developed as a subproduct of H2O) to Clang. Using H2O as a footstep, I am looking forward to bringing in new approaches for running / maintaining websites next year.
![はてなブックマーク - [Ann] Initial release of H2O, and why HTTPD performance will matter in 2015](http://b.hatena.ne.jp/entry/image/http://blog.kazuhooku.com/2014/12/ann-initial-release-of-h2o-and-why.html "はてなブックマーク - [Ann] Initial release of H2O, and why HTTPD performance will matter in 2015")






 を計算するプログラムを書けますか?")

")